
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- recommendation system
- coursera
- 협업 필터링
- wordcloud
- 추천 시스템
- 시각화
- selenium
- 추천시스템
- 코딩테스트
- 데이터
- Cosine-similarity
- Tensor
- codingtest
- 웹스크래핑
- 웹크롤링
- 알고리즘
- 백준
- 분산 시스템
- 데이터 엔지니어링
- 파이썬
- 머신러닝
- 코테
- Overfitting
- 딥러닝
- TF-IDF
- SGD
- 프로그래머스
- Python
- 부스트캠프
- pytorch
- Today
- Total
개발자식
[딥러닝] Batch Normalization 본문
Batch Normalization
- input data에 대해 Standardization과 같은 Normalization을 적용하면 전반적으로 model의 성능이 높아진다.
- 데이터 내 Column들의 Scale에 모델이 너무 민감해지는 것을 막아주기 때문이다.
- Batch 단위로 학습을 하게 되면 발생하는 Internal Covariant Shift 문제를 개선해준다.
->Internal Covariant Shift : 학습 과정에서 계층 별로 입력의 데이터 분포가 달라지는 현상

-> 신경망의 경우 Normalization이 제대로 적용되지 않으면 최적의 cost 지점으로 가는 길을 빠르게 찾지 못한다.

- 이러한 Normalization을 input data 뿐만 아니라 신경망 내부의 중간에 있는 Hidden layer로의 input에도 적용해준다.
- Activation function을 적용하기 전에 Batch normalization을 먼저 적용한다 (앞과 뒤 중 어느 쪽에 삽일할 지는 논의/실험 중)
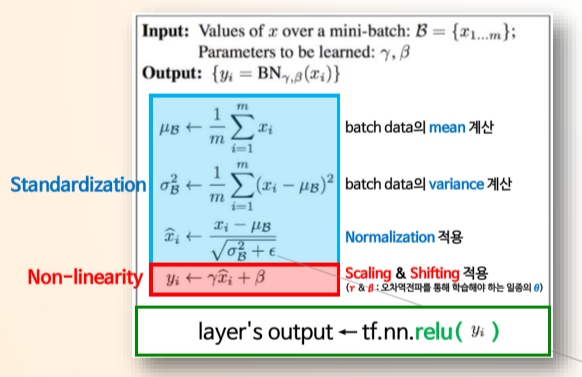
Batch Normalization process
1. 각 Hidden layer 로의 Input data에 대해 평균이 0, 분산이 1 이 되도록 Normalization을 진행한다
2. Hidden layer의 출력값 (output)이 비선형성을 유지할 수 있도록 Normalization의 결과에 Scaling (*γ) & Shifting (+β) 적용한다. (γ, β -> 일종의 파라미터 세타)
3. Scaling & Shifting 을 적용한 결과를 Activation function에게 전달 후 Hidden layer의 최종 output을 계산한다.

-> 위 그림과 같이 Scaling & Shifting을 적용하지 않으면 sigmoid의 입력값이 -1~1 사이로 출력 값의 형태가 거의 직선이다.
학습 단계의 배치 정규화
: 배치별로 계산되어야 각 배치들이 표준 정규 분포를 각각 따른다.
추론 단계의 배치 정규화
: 평균과 분산에 고정값을 사용한다
-> 테스트 단계에서는 배치 단위로 평균/분산을 구하기 어렵다.
-> 고정된 평균과 분산은 학습 과정에서 이동 평균 or 지수 평균을 통하여 계산한 값이다.
Batch Normalization의 장점
- 학습 속도 & 학습 결과가 개선된다 (Higer learning rate 적용 가능)
- 가중치 초기값에 크게 의존하지 않는다 (매 layer마다 정규화를 진행하므로 초기화의 중요도 감소)
- Overfitting을 억제한다 (dropout, L1/L2 regularization 등의 필요성 감소)
- 핵심은 학습 속도의 향상이다.

'AI > Deep Learning' 카테고리의 다른 글
| [딥러닝] 감성분석_BERT (0) | 2022.05.24 |
|---|---|
| [딥러닝] 딥러닝 Summary (0) | 2022.05.01 |
| [딥러닝] Avoiding Overfitting - Dropout (0) | 2022.05.01 |
| [딥러닝] 딥러닝 모델 최적화 이론_Batch (0) | 2022.05.01 |
| [딥러닝] 딥러닝 모델 최적화 이론_Weight Regularization (0) | 2022.05.01 |



