
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 웹스크래핑
- 파이썬
- 부스트캠프
- 웹크롤링
- pytorch
- 머신러닝
- 추천 시스템
- 협업 필터링
- Tensor
- Cosine-similarity
- TF-IDF
- 시각화
- codingtest
- recommendation system
- SGD
- 데이터
- wordcloud
- selenium
- 코딩테스트
- 코테
- 추천시스템
- coursera
- 데이터 엔지니어링
- Overfitting
- 분산 시스템
- 알고리즘
- 딥러닝
- Python
- 백준
- 프로그래머스
- Today
- Total
개발자식
[머신러닝] 교차 검증(CV_K-fold) 본문
데이터를 잘 설명하기 위한 올바른 복잡도를 가진 모델을 찾기 위한 방법 중 교차 검증 방법에 대해 알아본다.
교차 검증 (Cross Validation)
: 별도의 여러 세트로 구성된 학습 데이터 세트와 검증 데이터 세트에서 학습과 평가를 수행하는 것
교차 검증을 사용하는 이유
- 학습 데이터와 이에 대한 예측 성능을 평가하기 위한 별도의 테스트용 데이터가 필요한데 이 방법은 과적합 문제점을 가질 수 있으며 이를 개선하기 위해 사용한다.
- 과적합 (Overfitting) : 모델이 학습 데이터에만 과도하게 최적화되어, 실제 예측을 다른 데이터로 수행할 경우에는 예측 성능이 과도하게 떨어지는 것
(고정된 테스트 데이터에만 최적의 성능을 발휘하는 편향된 모델을 유도할 수 있고 결국 다른 테스트 데이터가 들어올 경우 성능이 저하된다.)
- 샘플의 수가 충분치 못한 경우 우연히 데이터를 어떻게 나누었는지에 따라 성능 차이가 많이 날 수 있어 모델 성능 결과가 변동되지 않기 위해 사용한다.
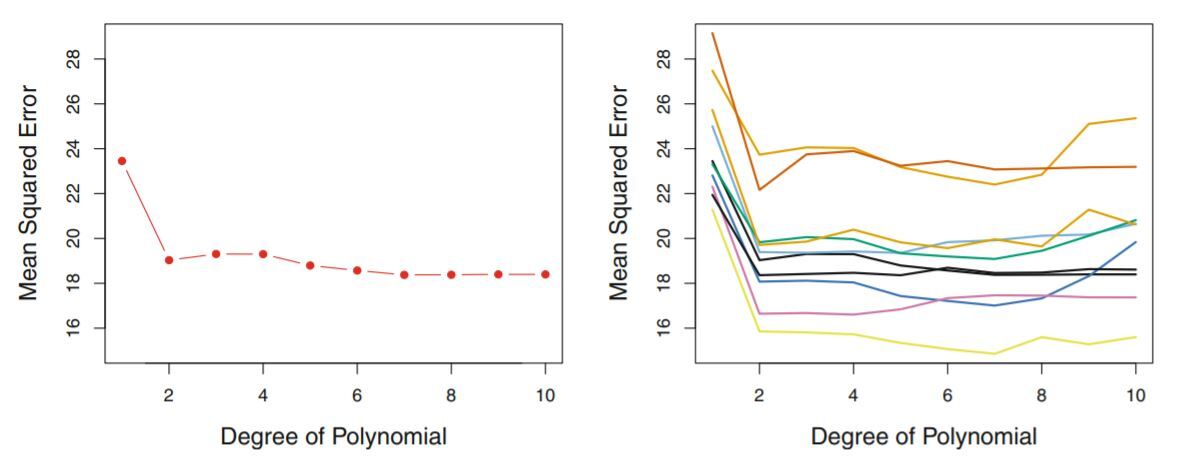
- 왼쪽 그림은 랜덤으로 데이터를 한번 나눈 뒤 validation의 mse를 본 경우이고 오른쪽 그림은 랜덤으로 데이터를 10번 다르게 나누었을 때 각각의 validation 편차가 어느 정도 나는지를 보여준다. 이를 통해 우연히 어떻게 나누었는지에 따라 mse값이 크게 달라진다. (validation의 variance가 크다)
Cross Validation iterators (반복자)
: 데이터 세트의 구조나 특성은 각 상황에 따라 천차만별이기 때문에 각 상황에 맞는 반복자를 사용해야 한다.
- 크게 아래 네가지로 구분 가능하다.
- 데이터들이 독립적이고 동일한 분포를 가진 경우
KFold, RepeatedKFold, LeaveOneOut(LOO), LeavePOutLeaveOneOut(LPO) - 데이터의 분포가 다른 경우
StratifiedKFold, RepeatedStratifiedKFold, StratifiedShuffleSplit - 데이터가 그룹화되어 있는 경우
GroupKFold, LeaveOneGroupOut, LeavePGroupsOut, GroupShuffleSplit - 데이터가 시계열 데이터인 경우
TimeSeriesSplit
K Fold Cross Validation
: k 개의 데이터 폴드 세트를 만들어서 k번만큼 각 폴드 세트에 학습과 검증 평가(교차 검증)를 반복적으로 수행하는 방법 (모든 데이터가 최소 한 번은 테스트 셋으로 쓰인다)

- 가장 보편적으로 사용되는 교차 검증 기법이다.
- 목적
: 1. 보지 않은 데이터에 대한 성능을 예측하기 위해
2. 여러번의 교차검증을 통해 모델들의 평균을 구하거나 최적의 모델을 구하는 것이다.
- 방법
: test set을 제외한 나머지 training set에 대해 k 등분하여 그중 1/k는 validation set으로 사용하고 (k-1)/k는 training set으로 사용하며, 이를 각 등분된 데이터 셋에 대해 총 k번 반복한다. 이를 통해 k개만큼의 모델을 만들고 각 모델의 mse값을 평균 내어 해당 모델의 mse값을 결정하게 된다.
- 해석
: mse의 평균값이 낮다는 것은 모델의 성능이 좋다고 평가할 수 있지만 mse의 분산이 높다면 데이터에 따라 성능의 편차가 커 실제 해당 모델을 사용할 경우 신뢰하기 어렵다. 평균값과 분산 모두를 고려하여 MSEavg+σ2의 결과를 모델 선택의 기준으로 삼을 수 있다.
- 적용
: 보통 회귀모델에 사용되며, 데이터가 독립적이고 동일한 분포를 가진 경우에 사용한다.
- 주의사항
: data set을 먼저 나눈 뒤 training set에만 전처리를 시행하고 다음 fold에 대한 교차검증 시에도 같은 기준으로 전처리를 진행하여 validation set과 test set에 영향이 없도록 한다.
- 장점
: 모든 데이터셋을 훈련에 활용하여 정확도를 향상시킬 수 있다. 데이터 부족으로 인한 underfitting을 방지할 수 있다.
test set에만 잘 작동하는 overfitting을 방지할 수 있다.
- 단점
: iteration 횟수가 많아져 단순히 training set / test set을 통해 진행하는 일반적인 학습법에 비해 시간 소요가 크다.
Stratified K-Fold Cross Validation
: K-Fold CV 와 비슷한 방법으로 수행되나 계층을 고려 하는 방법이다. 기존 K-Fold 방법을 사용한다면 데이터가 임의로 섞이면서 validation set에 특정 클래스가 과하게 분포될 수 있다. 극단적으로 전체 데이터 중 클래스 0이 80 %, 1이 20%라고 하면 어떤 fold에서는 아래의 사진과 같이 클래스 비율이 상이하게 분포되어 원치 않은 결과를 도출할 수 있다.

즉 아래 사진과 같이 전체 데이터의 비율을 고려하여 set을 구성한다.

- 일반적으로 클래스가 있는 분류 문제에서는 Stratified K-Fold CV를 활용하며 회귀 문제에서는 K-Fold CV를 활용한다.
cv외로 활용되는 방법들
- Cost function에 Regularization term 추가
- Drop-out & Batch Normalization (NN) 등
- Training Data를 많이 확보하거나 모델의 Feature를 줄이는 것도 좋은 방법
(+ Data augmentation & Test time augmentation)
'AI > Machine Learning' 카테고리의 다른 글
| [머신러닝] ROC Curve & AUC (0) | 2022.04.27 |
|---|---|
| [머신러닝] 로지스틱 회귀 (Logistic Regression) (0) | 2022.04.24 |
| [머신러닝] 머신러닝 학습 용어, Error (0) | 2022.04.24 |
| [머신러닝] 머신러닝 모델_XG Boost (0) | 2022.04.16 |
| [NLP] Konlpy, WordCloud (0) | 2022.03.29 |



